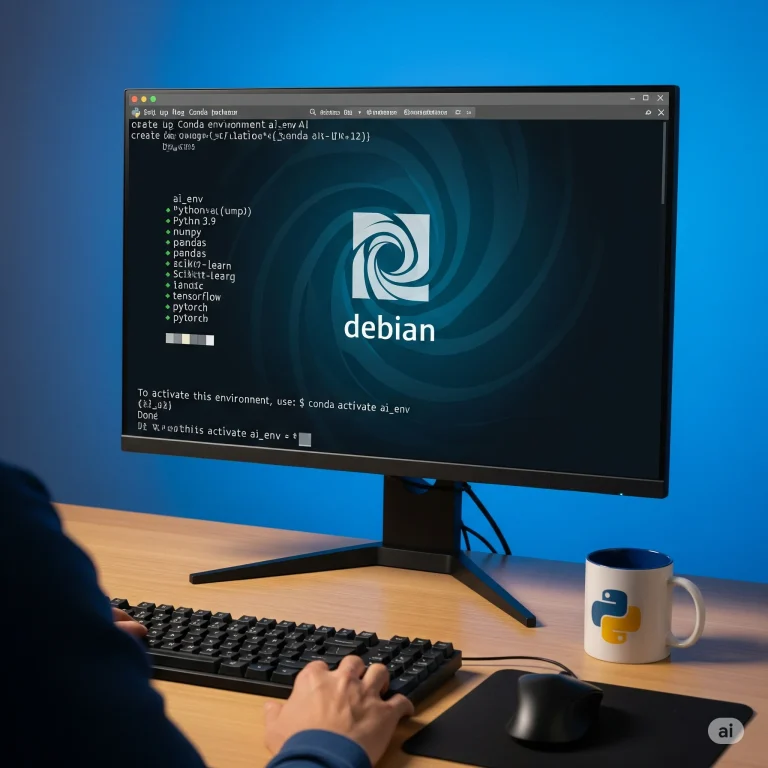
Anleitung: Einrichten einer KI-Python-Entwicklungsumgebung auf Debian mit Conda
Warum Conda für KI-Entwicklung? Conda ist ein leistungsfähiger Paket- und Umgebungsmanager, der das Verwalten von Python-Abhängigkeiten und virtuellen Umgebungen vereinfacht. Für KI-Projekte bietet Conda viele Vorteile:
- Unterstützt sowohl CPU- als auch GPU-basierte Bibliotheken wie PyTorch oder TensorFlow.
- Vermeidet „Abhängigkeitskonflikte“.
- Isoliert Umgebungen für verschiedene Projekte.
- Debian 12 oder neuer (Netinstall oder Desktop)
- Root- oder Sudo-Zugriff
- Grundlegende Terminalkenntnisse
Umfassende Anleitung: Debian mit Netinstall installieren (Grafisch & CLI)
Inhaltsverzeichnis
- Voraussetzungen
- Das Netinstall-Image herunterladen
- Bootfähiges Medium erstellen
- Grafische Installationsmethode
- CLI-Installationsmethode
- Konfiguration nach der Installation
- Fehlerbehebung
- Einen Computer mit mindestens 20 GB freiem Speicherplatz
- Mindestens 2 GB RAM (4 GB empfohlen für grafische Oberfläche)
- Eine stabile Internetverbindung
- USB-Stick (mindestens 4 GB)
- Debian Netinstall ISO-Datei
- Besuchen Sie die offizielle Debian Download-Seite: …

Umfassendes Tutorial: Systemweite Installation von Obsidian (AppImage) auf Debian
Überblick Dieses Tutorial führt dich durch die systemweite Installation von Obsidian (AppImage) in /opt, macht es ausführbar und erstellt .desktop-Dateien für bestehende Benutzer und alle zukünftigen Benutzer auf einem Debian-System. Voraussetzungen
- Debian-basiertes System
- sudo/root-Rechte
- Grundlegende Terminalkenntnisse

Erstelle deine eigenen KI-generierten Filme auf Debian: Eine Anleitung für Anfänger 🎬
Wolltest du schon immer deine eigenen Kurzfilme nur aus einer Textaufforderung oder einem Bild erstellen? Mit der Kraft der künstlichen Intelligenz ist das jetzt möglich! Dieses Tutorial führt dich durch die Installation und Verwendung von Stable Video Diffusion, einem leistungsstarken Open-Source-Modell, auf deinem Debian-System. Systemanforderungen Bevor wir loslegen, stellen wir sicher, dass dein System bereit ist. Das Ausführen von KI-Modellen kann ressourcenintensiv sein, daher brauchst du Folgendes:
- Betriebssystem: Debian 11 …

🧠 Tutorial: Verschleierung und Absicherung von KI-Modellen für die Bereitstellung – Ein Leitfaden zu Quantisierung, Verschlüsselung und Zugriffskontrolle
Sichere Bereitstellung > Modell-Obfuskation Unterkategorie von Cybersicherheit & Feinabstimmung Dieses Tutorial behandelt die Verschleierung von KI-Modellen, um Reverse Engineering, Manipulation oder Diebstahl zu verhindern – entscheidend für Entwickler, die proprietäre oder sensible Modelle auf Edge-Geräten oder Client-Servern bereitstellen. Einleitung Das Bereitstellen von KI-Modellen „in freier Wildbahn“ – egal ob auf Edge-Geräten, Client-Servern oder gemeinsam genutzten Umgebungen – birgt Risiken wie Modell-Leaks, Diebstahl oder Angriffe durch Dritte. Wenn du mit feinabgestimmten …

📘 Tutorial: LLaMA.Cpp Lokal unter Debian Ausführen – Ein Einsteigerfreundlicher Leitfaden für Privaten AI-Chat
Thema:: Lokale LLMs › Einrichtung von LLaMA.Cpp unter Debian für Offline-AI-Chat Das dürfte Nutzer*innen ansprechen, die Modelle lokal ausführen möchten, ohne sich auf Cloud-APIs zu verlassen. Einleitung Große Sprachmodelle (LLMs) wie ChatGPT haben unsere Interaktion mit Maschinen revolutioniert – aber die meisten setzen auf Cloud-Dienste, die Daten preisgeben und eine Internetverbindung erfordern. Du willst volle Kontrolle, Privatsphäre und keine OpenAI-API-Kosten? Dann ist llama.cpp genau richtig – eine blitzschnelle C++-Implementierung der LLaMA-Modelle von …